
Cube
Open-source analytics API and headless BI layer for engineering and analytics teams to build dashboards, embedded analytics, and consistent metric layers. Designed for data engineers, analytics engineers, and product teams who need programmatic access to pre-aggregated, cached analytics and a single source of truth for metrics.
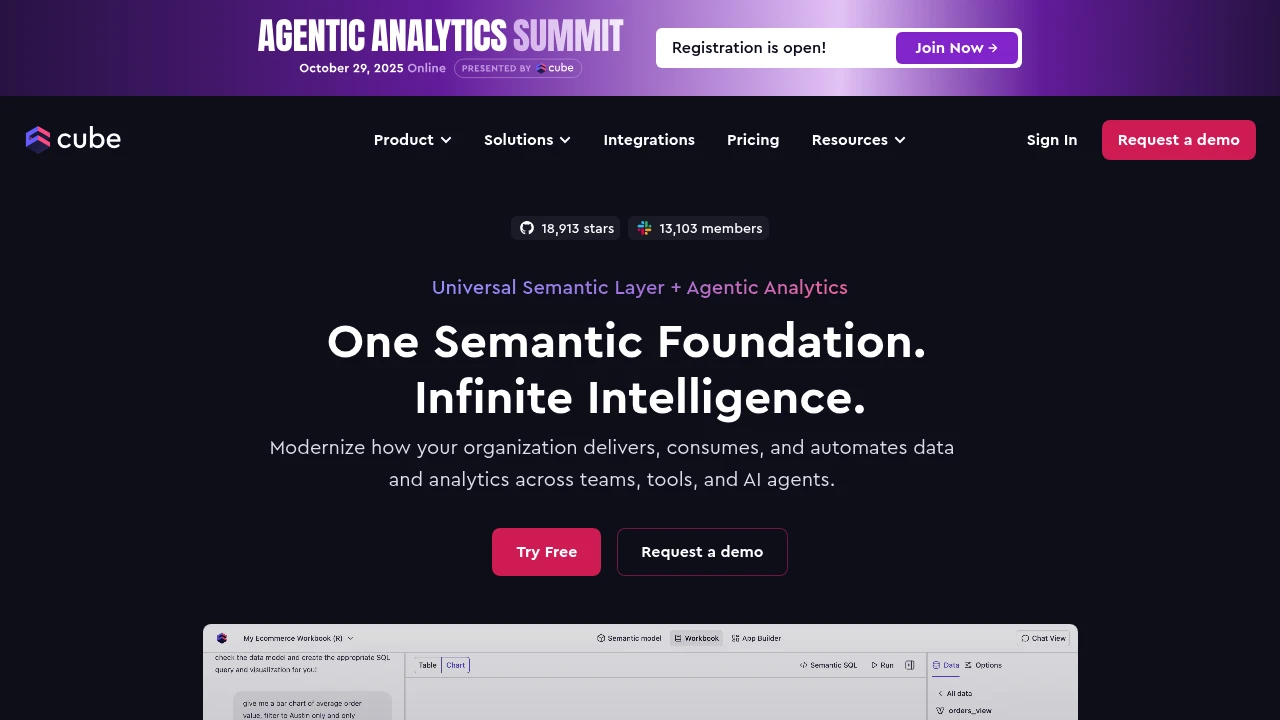
What is cube.dev
Cube.dev is an open-source analytics layer that exposes a programmatic analytics API for building dashboards, embedded analytics, and data products. The project provides both a self-hosted core (often referred to as Cube.js) and a managed offering (Cube Cloud) so teams can choose between running the stack in their infrastructure or using a hosted service. The core purpose is to turn raw data in warehouses and databases into performant, consistent analytical responses via a predictable JSON API.
Cube.dev focuses on three technical areas: query orchestration, pre-aggregation and caching, and schema-driven metric definitions. The schema (data model) sits in code and maps business concepts to underlying tables and SQL, enabling teams to define metrics once and reuse them across dashboards and embedded experiences. That schema-based approach enforces consistency for metrics across consumers.
The platform supports a wide range of SQL data sources via adapters and optimizes queries using on-the-fly or scheduled pre-aggregations. For teams that need operational analytics with low-latency responses, Cube.dev provides a configurable caching layer and strategies for incremental refresh of aggregates. For teams focused on product analytics or customer-facing reports, Cube.dev’s API-first design makes it simple to integrate analytics into web apps and internal tools.
Cube.dev is maintained as an open-source project with an active community and partner ecosystem. For more detail on architecture and deployment options, review Cube.dev’s documentation on architecture and deployment models at the official Cube.dev architecture documentation (https://cube.dev/docs/architecture).
Cube.dev features
Cube.dev combines developer-focused features and operational functionality intended for production analytics workloads. The core feature set includes: schema-driven metric definitions, pre-aggregations, flexible adapters for common warehouses, and an API layer that returns analytics results as JSON rather than embedding a UI. These features aim to give engineering teams full control over data modeling, caching, and query execution.
Key platform capabilities include: SQL adapters for databases and warehouses, a JavaScript-based schema language for defining cubes and measures, a query orchestration engine that translates high-level queries into optimized SQL, and a pre-aggregation framework that generates and refreshes summarized tables. The platform also offers role-based security at the query level and integration hooks for authentication and authorization in front-end apps.
Operational features that matter for production systems include autoscaling in the managed service, observability hooks (query logs and metrics), and incremental refresh for pre-aggregations so refreshes are efficient. The managed Cube Cloud adds a UI for monitoring and controlling pre-aggregations, team access, and runtime settings while the self-hosted core gives maximum control for custom deployments.
Cube.dev integrates with common data tooling and visualization platforms via its API and connectors. Teams can embed analytics directly into applications using client SDKs, or connect BI tools to Cube.dev via the SQL layer or through connector tooling. See the Cube.dev connectors and integrations documentation for a complete list of supported sources and clients: Cube.dev integrations and connectors (https://cube.dev/docs/connectors).
What does cube.dev do?
Cube.dev exposes a headless analytics API and a repeatable metric layer so teams can serve analytical data to dashboards, embedded UIs, and customer-facing reports. Instead of shipping a monolithic BI product, Cube.dev provides the backend pieces—model definitions, caching, and query execution—so front-end developers and BI tools can retrieve consistent metric values.
It turns user-level or event-level data in a data warehouse into pre-aggregated tables and cached query results that return in sub-second to low-second latencies for common queries. The system orchestrates creation and refresh of pre-aggregations, chooses the appropriate materialized view for a query, and falls back to generating SQL dynamically when needed.
Cube.dev also simplifies complex data modeling tasks by letting analytics engineers express dimensions, measures, and joins in a code-first schema. That schema becomes the single source of truth for metrics used across dashboards and embedded components, reducing discrepancies between reports and manual SQL queries.
Cube.dev pricing
Cube.dev offers these pricing plans:
- Free Plan: $0/month — open-source self-hosted core available under the project license. Intended for developers and small teams who want to run Cube.dev on their own infrastructure with full access to the schema and query engine.
- Starter: $199/month — managed Cube Cloud tier for small production deployments. Includes hosted runtime, basic support, limited pre-aggregation compute and storage, and core observability features.
- Professional: $999/month — managed tier for production analytics at scale with larger usage quotas, enhanced caching and pre-aggregation capacity, priority support, and team administration features.
- Enterprise: Custom pricing — includes dedicated infrastructure options, single sign-on (SSO), audit logs, compliance controls, on-premises deployment support, and a service-level agreement.
Check Cube.dev's current pricing for the latest rates and enterprise options.
Cube.dev pricing
Cube.dev offers these pricing plans:
- Free Plan: $0/month — self-hosted open-source core with community support
- Starter: $199/month — managed cloud for small teams
- Professional: $999/month — production-ready managed cloud for larger teams
- Enterprise: Custom pricing — tailored for large organizations
Check Cube.dev's current pricing for the latest rates and enterprise options.
How much is cube.dev per month
Cube.dev starts at $0/month for the open-source self-hosted core. For teams that prefer the managed offering, Cube Cloud starts at $199/month for the Starter plan when billed monthly for hosted runtime and basic support.
How much is cube.dev per year
Cube.dev costs $2,388/year for the Starter plan when billed annually at the monthly equivalent of $199/month. The Professional and Enterprise tiers are billed at higher annual rates or on custom contracts depending on usage and service level.
How much is cube.dev in general
Cube.dev pricing ranges from $0 (open-source self-hosted) to custom enterprise pricing. Small teams can run the open-source core for free on their own infrastructure, while managed Cube Cloud pricing typically starts in the low hundreds per month for Starter and scales to higher monthly or annual fees for professional and enterprise needs.
What is cube.dev used for
Cube.dev is used to build backend analytics services that power dashboards, embedded analytics, and internal reporting applications. The platform is particularly useful when teams need a consistent metric layer that multiple applications and teams will consume. By defining metrics in a single schema, organizations reduce duplication of SQL logic and avoid drifting definitions between reports.
Common uses include product analytics APIs (session counts, retention, funnels), customer-facing analytics for SaaS products (white-labeled reports embedded into customer portals), operational dashboards for business metrics (revenue, churn, gross margin), and internal analytics portals used by sales and support teams. Cube.dev’s pre-aggregation features make these scenarios feasible at low latency even when underlying datasets are large.
Teams also use Cube.dev as a translation layer between visualization tools and raw data warehouses. Instead of allowing every dashboard author to write raw SQL against the warehouse, Cube.dev provides a guarded layer that enforces joins, access controls, and approved measures.
For engineering teams building data products or analytics-driven features, Cube.dev is useful because it is API-first and code-centric; it integrates directly into application architecture and supports automated CI/CD for analytics schema changes.
Pros and cons of cube.dev
Cube.dev offers strong advantages around consistency, performance, and developer control. Because metric definitions live in code, teams can version control schema changes, run tests, and roll out metadata changes through existing deployment processes. The pre-aggregation framework reduces query loads on the warehouse and improves response times for common queries.
The managed Cube Cloud reduces operational overhead by taking care of runtime scaling and maintenance, while the self-hosted open-source core provides flexibility for teams that must run analytics in their environment for compliance or latency reasons. The extensible adapter architecture supports many warehouses and databases, so Cube.dev fits into diverse data stacks.
On the downside, running Cube.dev introduces operational complexity compared with fully hosted end-to-end BI platforms that include a UI. Implementing a code-first schema requires engineering resources and discipline from analytics engineers; smaller teams without dedicated engineering support might find setup and maintenance a barrier. Pre-aggregation design and sizing also require some planning to avoid over-consuming compute and storage.
Another limitation is that Cube.dev is headless: it provides the API and modeling but not a full-fledged visualization product. Teams that want an out-of-the-box dashboarding surface will need to pair Cube.dev with a front-end library, a JavaScript visualization stack, or a BI tool that consumes Cube.dev’s outputs.
cube.dev free trial
Cube.dev’s open-source core is available immediately and free to self-host, which serves as a working trial for developers who want to evaluate the platform in their environment. For the managed service, Cube Cloud typically offers a trial period or free tier that lets teams validate performance, integrations, and the pre-aggregation workflow without committing to a paid plan.
During a managed trial, teams should test three things: integration latency with the chosen data source, the behavior and refresh windows of pre-aggregations, and how the Cube.dev schema maps to the business’s canonical metrics. These aspects determine whether the platform meets the SLA and latency targets required by production dashboards and embedded analytics.
If you prefer an official, up-to-date description of trial and free-tier options, view Cube.dev’s documentation on the managed offering and free self-hosted options at the Cube.dev pricing and plans documentation (https://cube.dev/pricing).
Is cube.dev free
Yes, cube.dev is available as an open-source project and can be run for free self-hosted. The core engine and schema framework are open source, which lets teams experiment, develop, and run the system without subscription fees. Managed Cube Cloud, additional support, and enterprise features are paid.
Cube.dev API
Cube.dev exposes a programmatic analytics API that returns results in JSON. The query layer accepts high-level query objects (dimensions, measures, filters, time dimensions) or SQL directly, translates those requests into optimized SQL for the underlying data source, and returns a JSON payload that is convenient for front-end consumption. The API supports pagination, caching headers, and query metadata for observability.
There are client libraries and SDKs that simplify calling the API from JavaScript front ends and server applications. The platform also provides a SQL API for advanced users who need direct SQL access or who want to integrate Cube.dev with BI tools that can speak SQL. For implementation patterns and SDK reference, consult Cube.dev’s API reference and SDK docs (https://cube.dev/docs).
From an integration standpoint, Cube.dev supports a range of connectors for databases and warehouses (Postgres, MySQL, Snowflake, BigQuery, Redshift, ClickHouse, etc.). The system can run pre-aggregations as tables inside the same warehouse or in an external cache store, and it supports using caching layers like Redis for query result caching to further reduce latency. Security integration points include SSO, token-based authentication for the API, and row-level security implemented in the schema layer.
10 Cube.dev alternatives
- Looker — cloud BI and semantic modeling platform with a hosted modeling layer (LookML) and native visualization.
- Apache Superset — open-source data exploration and visualization platform with a SQL-centric UI and plugin ecosystem.
- Metabase — open-source BI and dashboarding tool that emphasizes quick setup and non-technical user queries.
- Mode Analytics — analytics platform combining SQL notebooks, charts, and reporting with tight collaboration features.
- ThoughtSpot — search-driven analytics with a focus on ad-hoc natural language queries and self-service insights.
- Chartio — (note: product acquisitions changed availability) historically a simple cloud BI tool suitable for small teams.
- Periscope Data (by Sisense) — analytical platform focused on SQL-first data analysis and reporting for data teams.
- Redash — open-source query and visualization tool that connects to many data sources and supports query scheduling.
- Holistics — data modeling and scheduling platform with a combined modeling and reporting workflow.
- Cube Cloud competitors (various vendor managed stacks) — includes managed analytics layers that offer similar hosted APIs and metric governance.
Paid alternatives to cube.dev
- Looker — enterprise-grade semantic modeling and BI platform with a modeled layer, embedded analytics support, and vendor-managed hosting. Looker’s cost reflects enterprise features like governance, support, and embedded analytics tooling.
- ThoughtSpot — built for search-driven analytics and rapid ad-hoc exploration with AI-driven insights and enterprise-grade scaling and support.
- Mode Analytics — commercial offering that blends SQL notebooks and visualization for collaborative analytics teams; pricing tiers accommodate heavier query loads and collaboration features.
- Sisense (Periscope lineage) — platform focused on embedded analytics and dashboarding with both cloud and on-premises deployment options and commercial support.
- Tableau (Server/Cloud) — established visualization platform that can be used with semantic layers and embedded via APIs; enterprise-focused pricing and features.
Open source alternatives to cube.dev
- Apache Superset — open-source visualization and exploration platform that connects to many SQL databases, useful for creating dashboards and exploratory queries.
- Redash — open-source query and dashboard tool for teams that prefer SQL-first workflows and scheduled queries.
- Metabase — open-source BI with an emphasis on ease-of-use for non-technical users and quick setup for product and support teams.
- Druid + custom API layer — for teams focused on real-time OLAP, a stack built on Apache Druid plus a custom API can substitute Cube.dev’s pre-aggregations and query layer.
- ClickHouse with custom services — high-performance columnar stores coupled with a developer-built API and aggregation layer can be a direct open-source alternative for high-throughput analytics.
Frequently asked questions about Cube.dev
What is cube.dev used for?
Cube.dev is used as a headless analytics layer and metrics API to power dashboards, embedded analytics, and internal reporting. It converts warehouse data into consistent measures and pre-aggregated results so applications and BI tools can consume analytics via a JSON or SQL API.
Does cube.dev offer a managed cloud?
Yes, Cube.dev offers Cube Cloud as a managed service that hosts runtime, manages pre-aggregation compute, and provides monitoring and team management features. The managed option removes much of the operational burden of self-hosting while preserving the same schema and API model.
Can I self-host cube.dev?
Yes, the core of cube.dev is open-source and can be self-hosted. Organizations can deploy the engine in their own infrastructure or Kubernetes cluster and connect it to their data warehouses and cache layers.
What data sources does cube.dev support?
Cube.dev supports a wide range of SQL databases and warehouses including Postgres, MySQL, Snowflake, BigQuery, Redshift, ClickHouse, and others via adapters. It can also integrate with caching stores for result caching and materialized pre-aggregations.
How does cube.dev improve query performance?
Cube.dev improves performance through pre-aggregations and query caching. The engine generates and refreshes materialized tables and selects the optimal aggregation for a given query to minimize runtime work on the data warehouse.
Is cube.dev suitable for embedded analytics?
Yes, cube.dev is designed for embedded analytics and data products. Its API-first design, client SDKs, and ability to define a single metric layer make it straightforward to embed analytics into customer portals and SaaS applications.
Does cube.dev provide authentication and security features?
Cube.dev provides hooks for authentication and supports role-based access in the schema layer. Teams typically integrate the Cube.dev API with their application authentication (JWT, SSO) and implement row-level security through schema filters.
Can I version control cube.dev schemas?
Yes, cube.dev schemas are code-first and intended to be version controlled. Schemas are defined in files that can be placed under Git, enabling CI/CD workflows for analytics model changes and reviews by engineering teams.
How do pre-aggregations work in cube.dev?
Pre-aggregations are materialized summaries created by Cube.dev to accelerate queries. You define measures and aggregation rules in the schema; Cube.dev generates the underlying SQL and manages refresh schedules and incremental updates to keep these aggregates up to date.
What client libraries does cube.dev offer?
Cube.dev offers client SDKs and examples for JavaScript, Node.js, and front-end frameworks. These SDKs simplify building queries against the analytics API and embedding charts and dashboards in web applications; additional community SDKs and integrations are available for other languages and frameworks.
cube.dev careers
Cube.dev (the organization behind the open-source project and Cube Cloud) typically hires for roles across engineering, developer advocacy, product, support, and sales. Engineering roles focus on backend systems, query optimization, adapters for warehouses, and managed service infrastructure. Developer-facing roles include documentation authors, developer advocates, and community managers who help guide adoption and contribute to open-source ecosystem growth.
Candidates should look for positions that match experience in distributed systems, SQL optimization, and cloud-native deployment (Kubernetes, Docker). For roles related to Cube Cloud, experience with multi-tenant systems, observability and monitoring, and operational security is frequently sought. To find current openings and application instructions, check Cube.dev’s careers listings and company pages on major job boards.
Cube.dev also encourages contributions to the open-source repository; contributing to the codebase and community modules can be a practical way for engineers to demonstrate interest and fit for technical roles. Community involvement and contributions are often visible indicators of relevant expertise for hiring teams.
cube.dev affiliate
Cube.dev does not publish a widely promoted affiliate program in the same manner as consumer SaaS. Partnerships typically take the form of technology partners, integration partners, and reseller or systems integrator agreements. Companies that build products or services on top of Cube.dev may pursue commercial partnership discussions with the Cube organization for co-marketing, implementation support, or managed deployment arrangements.
If you are interested in partnership opportunities, reach out via the official Cube.dev contact and partnership pages or review the partner information in Cube.dev’s commercial documentation. Vendor partnerships can include referral terms, joint go-to-market arrangements, or implementation services depending on the size and scope of engagements.
Where to find cube.dev reviews
Public reviews of Cube.dev and Cube Cloud can be found on technology review sites and developer forums. Look for user reviews on platforms that cover developer tools and BI platforms and check case studies and technical blogs that document real-world implementations. For hands-on impressions, developer community discussions on GitHub Issues, Stack Overflow, and Reddit provide practical insights into integration effort, operational considerations, and edge-case behaviors.
For enterprise procurement, ask for references and case studies from the vendor and request a proof-of-concept that mirrors your production data volumes to validate performance. Also consult Cube.dev’s documentation and community resources for benchmarks and deployment guides: Cube.dev documentation (https://cube.dev/docs).


